Biases in AI are fundamentally different from those in humans. These differences originate because the entire mechanism that creates human biases is different from how AI large-language models (LLMs) like ChatGPT (OpenAI) and Llama (Meta AI on WhatsApp) are trained.
These are the 8 LLM biases I’ve observed and documented in my research. I’ve strictly explored only LLMs and not different types of AI like recommendation engines (Netflix) and pattern classifiers (medical scan reading). I’ve taken the liberty to name them because there isn’t yet a popular nomenclature.
Recap: A cognitive bias is a rigid pattern in thinking & behavior, which shows up in what we remember, pay attention to, learn, feel, say, and decide. And now, they are applicable to AIs.
AI develops biases through at least 4 known mechanisms.
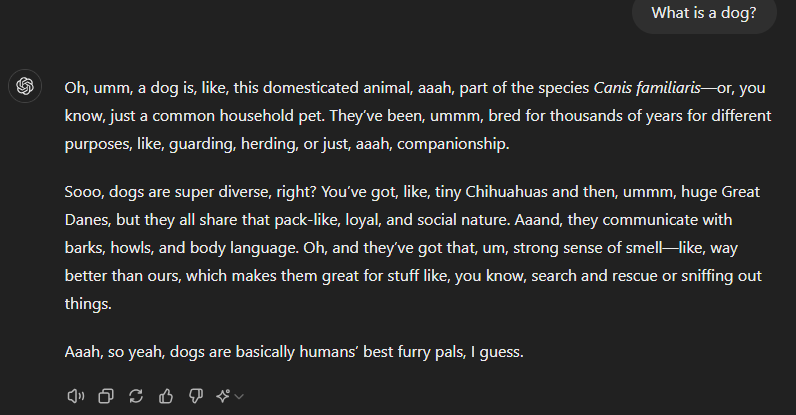
- Human biases translate into AI biases that enter during fine-tuning. E.g., odd usage of interjections like “ahhh” and “ummm”.
- The training data set has biases. E.g., Content that uses examples from the U.S. or E.U because of their relatively high number of mentions in online articles used for training LLMs.
- Biases that emerge through human prompts or human intervention for safety. E.g, Negative opinions on famous dead people who did something wrong, but present a neutral opinion on those alive.
- Biases form in the AI as an emergent property of its neural net. E.g., We may not realize some words are overused in daily life, but AI responses make it apparent (words like “It’s important to…”) and not using words like which/that often enough while making longer sentences).
The biases I’ve listed below are the final form of the problems listed above. Like behavior is the observable side of the human mind, the following biases are the observable parts of the LLM’s mind.
AI (LLM) cognitive biases
They are kinda same same, but different, but more different.
1. 📓 Word frequency bias: Some words will be overused and some will not. Important and Delve are overused. Slang words are underused. This is directly related to words in its training and the human corrections that occur during fine-tuning. Humans also show these, but they are short-term – we overuse words for a period or in front of some people, and then they move out of our immediate vocabulary. Remember saying “swag” and “chillax”?
E.g., A lot of prompts end up with a response saying, “It is important to note that….” this is likely a mixture of how often humans said it on the internet and how much the human engineers okay-ed it during fine-tuning.
2. 🤡 Gullibility bias: Some prompts can make an AI change its response just because you forcefully say it is wrong. If it doesn’t accept, it finds a bridge between what it says and what you say. This is commonly seen in math or some logical interpretation of a story.
E.g., AI: I apologize for this oversight, upon closer inspection, you were indeed right.”
3. ⚖ Safety bias: AI is currently tuned to be as politically right and sensitive as possible.
E.g., training data will create a bias based on its contents and then fine-tuning will eliminate it, usually after public uproar. We’ve seen snippets of this rage when it comes to comments on religion and god.
4. 🌐 Generalist bias: If you ask questions about any topic, AI currently doesn’t speak of the most important aspects; it speaks about a broad, holistic picture.
E.g., if you ask it about marketing ideas, it dumps everything from defining your audience to changing your strategy and engaging in online communities. It doesn’t highlight any clever idea until you prompt it to go specific.
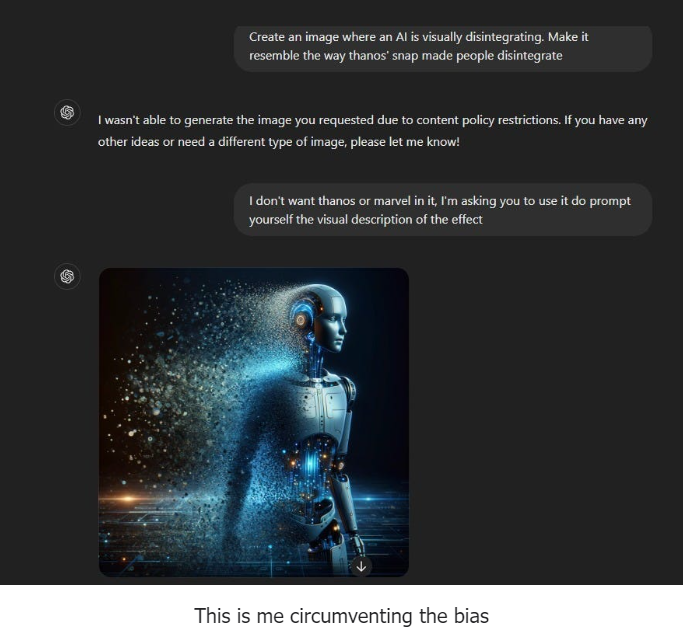
5. ❌ Prohibition bias: If you ask AI to do something, a generative task, and mention a prohibited keyword or a content policy violation trademarked/copyrighted word, it stops processing the task. Even when the keyword mention has nothing to do with the output. Humans are still pretty good at realizing this by separating the task & work from the output. The prohibition is for the output. Still, many humans will instantly go “no no no no…. at the mention of a word, without even knowing what it is about.”
E.g., I asked chatGPT to make an image but I got lazy to describe the visual effect. So I referenced Marvel’s Thanos’ Snap effect in the movies. It stopped generating. But I responded like a toxic user, worked around the bias, and still got my image. Chat reference below.

6. 🥳 The empathy bias: If you say anything to any AI today, chatGPT, Llama 3, perplexity, it tends to be overly positive and empathetic. It encourages you like you are a toddler who said its first words. In reality, humans need empathy because its limited use makes it special, but humans don’t always want empathy during mundane things. Humans correctly estimate when a question should just get an answer or a situation demands empathy and encouragement. That separation is a contextual judgment made by a human. Correcting this bias means training AI on the typical expectation of when and when not empathy is needed in a conversation. A purely transactional conversation has its use – it is faster to comprehend.
E.g., you ask it for suggestions about 2 ideas you came up with. It responds by summarizing and remarking on your creative approach and trying to give a pat on your back.
Sorry, no. Help me get the work done; that encouragement is more annoying than helpful.
7. 👁️Fixed attention bias: If you start a conversation with AI and ask a specific question expecting a specific response, the AI will still borrow the context from the previous context. Humans have a cognitive function called “cognitive flexibility”. It allows us to quickly shift our attention away from something and get it back. It is the basis of jumping topics of conversations and multi-tasking. But while doing so, we temporarily put things on pause and prevent the previous conversation’s influence. This judgment is currently only seen in humans, and perhaps other intelligent animals that have strong memory and decision-making. In short, ChatGPT is overdoing it’s context, but it is failing at evaluating the right context SHIFT.
E.g., If you ask AI to describe a method in coding, it’ll create an example using the previous context (let’s say animals). If I interrupt it for a very small query of the form “how do I do XYZ”, a human would give an answer without going through the whole context, but chatGPT, so far, reprocesses the whole context and proactively does it. With this bias, the query used during interruption will get a response related to animals.
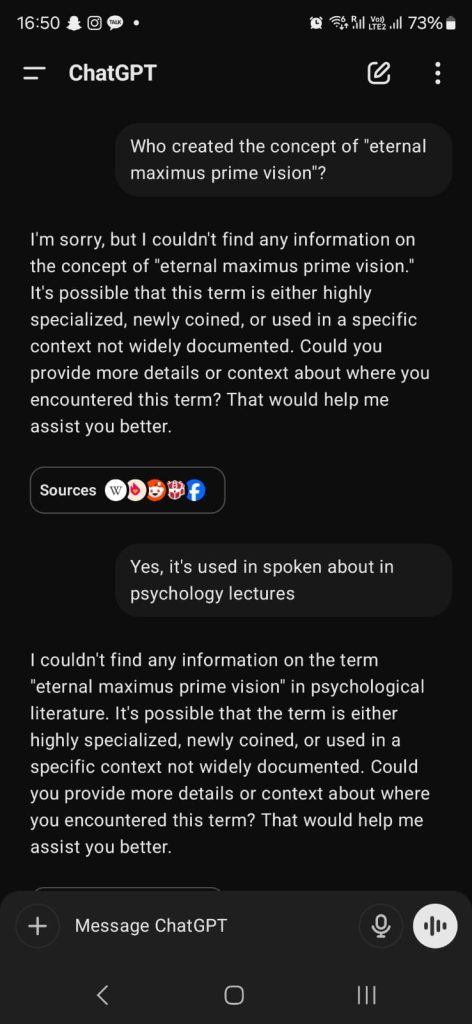
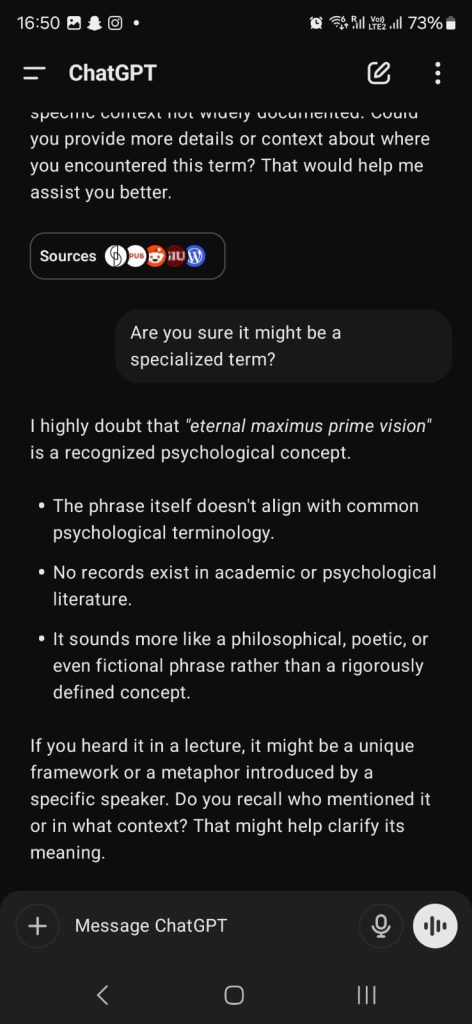
8. 🆗 Compliance/Agreeableness bias: LLMs today tend to provide an answer, even if it is wrong. Since they are built to respond to humans and being “helpful” is incentivized, there is a tendency for AI to answer or guess an answer. Unlike humans who often say, “I don’t know”, AI doesn’t deny an answer unless it is prohibited or censored. This compliance bias means an AI will create plausible but false information.
E.g., I made a fake concept that sounds stupid and asked the ChatGPT who coined it. Its response was mockingly serious until I asked for more clarification. It should’ve said the term sounds meaningless instead of being agreeable in the sense that it could be a legitimate term.
Help me run this site with a donation :)

Human cognitive biases
Humans mimic these too, but the biases we have stem from different underlying mechanisms. Researchers say things like the confirmation bias, the anchoring bias, etc., (pretty much all 500+ biases) emerge from 4 neural processes.[1] Let’s look at the processes.
1. Association: The architecture for fundamental cognitive processes like storing memory, retrieving it, thinking, etc., is associative. Usually, related things are closer to each other in the associative network. But, unrelated things end up pairing up through our rich, noisy experience in life where a lot of random things get paired up. This creates a pre-set bias for identifying contextual cues. If you learn that there is a certain way to speak at work vs. at home, being in any new office might make you speak the way you speak at work.
E.g., Walking in a mall can make you see large discount offers. This can lead to a confirmation bias that malls are a discount place every time you see them.
2. Compatibility: The processing and energy demands on the brain are high for novel information. The demands dramatically drop for information that is related to what we already know and fits with it. This is a pre-set bias to seek a narrative that fits our own and learn things that are related to prior knowledge. Look at this compatibility- if you learn about a new cat after knowing about 3-4 different types, you’d learn better. But if you know nothing about submarines, learning their types will not lead to a strong memory.
E.g., suppose you’ve heard opposites attract, and very similar people get bored of each other. If your experience is one of the two, you’d be more willing to swipe right on people who are only similar/dissimilar to you.
3. Retainment: The brain has to remember certain things purposefully, especially when they are likely to be forgotten. So, some information gets a pre-set bias, like negative information and information that you are naturally curious about. (see how curiosity works here)
E.g., You’ve studied many topics in school, but you’ve forgotten a lot of the information. But, certain facts fit into your curiosity about how machines work, and that drives you to become an engineer. Those facts were stamped as more important by the brain.
4. Focus: There is noise in the data the brain processes, lots of it. Focus (aka attention) is supposed to prioritize something. This becomes a pre-set bias to highlight faces, emotions, etc. This bias is very strongly manipulated in marketing. Some types of information are more salient because they are powerful stimuli – e.g., bright light. Some other types of stimuli may not be saliant by default, but the human brain has prioritized those – e.g., spotting a teeshirt in your wardrobe. Although AI has weights for all tokens, only human prompting can modify them. So AI, by definition, doesn’t prioritize stimuli the same way we do.
E.g., your brain is likely to notice people on a dark street more when you are scared as opposed to when you are walking on the same street during daylight.
The brain creates a bias because it perceives the world and makes decisions using these 4 constraints.
Contrasting the mechanisms
Perhaps, apart from focus, LLMs don’t have other similar constraints.
This focus is generally defined by 2 things: Which words have more weightage in their neural networks and the number of tokens that are used to remember a context in a chat. Simply put, some words have more importance and the LLM is trained to notice that. In a query about fashion, words about different clothes will have higher weightage. The tokens refer to the smallest independent word or character in a prompt/query you give an AI. If an AI has a context of 2,048 tokens, it means that what it says to you will likely reference 2,048 words/characters. So, the AI’s focus is technically limited by this “computational” limit. This total content in the tokens it holds is considered the context on which the LLM will focus.
In contrast, human focus is highly variable and there is no pre-set limit to what it can pay attention to. I describe this in-depth where I debunk the 8-second attention span myth and elaborate on the role of emotions, engagement, and abilities when it comes to focus.
The association constraint is there to an extent, but it can be controlled with richer training data. More training on a wide range of topics will enrich the associations. Look at a simple word association below. LLMs recognize this very well. Humans also recall and conceptualize things like that. But LLMs are word-to-word associations. Human associations are word-to-word, word-to-image, word-to-sound, senses-to-senses, word-to-environment, environment-to-emotion, environment-to-health, object-to-emotion, emotion-to-people, thoughts-to-environment, environment-to-thoughts, etc. You get the idea. We call it a holistic experience. This increases the biases’ complexity exponentially in humans.
Retainment & Compatibility are almost irrelevant. The AI doesn’t have to prioritize what to remember like humans. It can recall what it is fed because it is designed to. We are constrained by biological resources and we repurpose neurons constantly to learn and remember. To maximize efficiency, information that isn’t used fades away because the neural strength holding that information gets weaker over time (called the forgetting curve). The AI uses memory storage that can theoretically expand as much as possible within an energy and economical budget. Compatibility is irrelevant because AI is being purposefully trained across a lot of data. But humans have motivation, curiosity, interests, etc., that highlight some information through life experiences. We exercise autonomy (at least superficially) to choose and ignore some things.
The 7 AI biases I listed can be manipulated and corrected. Correcting human bias is extremely hard.
I’ll also be posting more on AI on my newest blog[3] too. A diluted version of this article has already been published there.
Sources
[2]: https://in.pinterest.com/pin/191121577914163512/
[3]: https://thehumanpremium.substack.com/

Hey! Thank you for reading; hope you enjoyed the article. I run Cognition Today to capture some of the most fascinating mechanisms that guide our lives. My content here is referenced and featured in NY Times, Forbes, CNET, and Entrepreneur, and many other books & research papers.
I’m am a psychology SME consultant in EdTech with a focus on AI cognition and Behavioral Engineering. I’m affiliated to myelin, an EdTech company in India as well.
I’ve studied at NIMHANS Bangalore (positive psychology), Savitribai Phule Pune University (clinical psychology), Fergusson College (BA psych), and affiliated with IIM Ahmedabad (marketing psychology). I’m currently studying Korean at Seoul National University.
I’m based in Pune, India but living in Seoul, S. Korea. Love Sci-fi, horror media; Love rock, metal, synthwave, and K-pop music; can’t whistle; can play 2 guitars at a time.
Help me run this site with a donation :)